
Sorted hash clusters combine the qualities of the hash cluster just described with those of an IOT. They are most appropriate when you constantly retrieve data using a query similar to this:
Select *From tWhere KEY=:xOrder by SORTED_COLUMN
That is, you retrieve the data by some key and need that data ordered by some other column. Using a sorted hash cluster, Oracle can return the data without performing
a sort at all. It accomplishes this by storing the data upon insert in sorted order physically—by key. Suppose you have a customer order table:
The table is stored in a sorted hash cluster, whereby the HASH key is CUST_ID and the field to sort on is ORDER_DT. Graphically, it might look like Figure 10-10, where 1, 2, 3, 4, … represent the records stored sorted on each block.
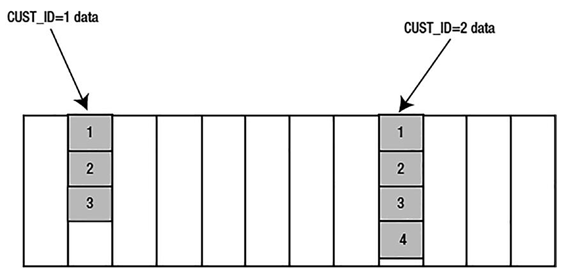
Figure 10-10. Depiction of a sorted hash cluster
Creating a sorted hash cluster is much the same as the other clusters. To set up a sorted hash cluster capable of storing the preceding data, we could use the following:
SQL> CREATE CLUSTER shc(cust_id NUMBER,order_dt timestamp SORT)
We’ve introduced a new keyword here: SORT. When we created the cluster, we identified the HASH IS CUST_ID, and we added an ORDER_DT of type timestamp with the keyword SORT. This means the data will be located by CUST_ID (where CUST_ID=:x) and physically retrieved sorted by ORDER_DT. Technically, it really means we’ll store some data that will be retrieved via a NUMBER column and sorted by the TIMESTAMP. The column names here are not relevant, as they were not in the B*Tree or HASH clusters, but convention would have us name them after what they represent.
We’ve mapped the CUST_ID column of this table to the hash key for the sorted hash cluster and the ORDER_DT column to the SORT column. We can observe using AUTOTRACE in SQL*Plus that the normal sort operations we expect are missing when accessing the sorted hash cluster:
SQL> select job, hiredate, empnofrom scott.empwhere job = ‘CLERK’order by hiredate;
SQL> set autotrace off
I added the query against the normal SCOTT.EMP table (after indexing the JOB column for this demonstration) to compare what we normally expect to see: the SCOTT.EMP query plan vs. what the sorted hash cluster can do for us when we want to access the data in a FIFO mode (like a queue). As you can see, the sorted hash cluster has one step:
it takes the CUST_ID=:X, hashes the input, finds the first row, and just starts reading the rows, as they are in order already. The regular table is much different: it finds all of the JOB=’CLERK’ rows (which could be anywhere in that heap table), sorts them, and then returns the first one.
So, the sorted hash cluster has all the retrieval aspects of the hash cluster, in that it can get to the data without having to traverse an index, and many of the features of the IOT, in that the data will be sorted within that key by some field of your choice. This data structure works well when the input data arrives in order by the sort field, by key. That is, over time the data arrives in increasing sort order for any given key value. Stock information fits this requirement as an example. Every night you get a new file full of stock symbols, the date (the date would be the sort key, and the stock symbol would be the hash key), and related information. You receive and load this data in sort key order. The stock data for stock symbol ORCL for yesterday does not arrive after today—you would load yesterday’s value, and then today’s value, and later tomorrow’s value. If the information arrives randomly (not in sort order), this data structure quickly breaks down during the insert process, as much data has to be moved to put the rows physically in order on disk. A sorted hash cluster is not recommended in that case (an IOT, on the other hand, could well be useful for that data).
When considering using this structure, you should employ the same considerations from the hash cluster section, in addition to the constraint that the data should arrive sorted for each key value over time.